Dear readers,
I hope that you are as curious as I am and join me on this learning journey. So, get your curiosity and development environment ready and let’s get started. 🙂
To begin with, I will guide you through some hopefully not so boring terminology.
What is RAG?
R = Retrieval A = Augmented G = Generation
Flow without RAG
- Original prompt usually as an user specific input.
- The original prompt is sent directly to the LLM.
- The LLM responds based on a large amount of generic data that it was trained and is likely to be out of date.
Flow with RAG
- Original prompt usually as an user specific input.
- Retrieval of additional context and information based on the domain. For example, a company specific data.
- The original prompt is considered together with the extra context that has been retrieved in step 2 and both are sent to the LLM.
- LLM responds based on the up to date information it has been provided with.
What needs to be done to build RAG?
- Collect and create the context specific data - This can be achieved by, for example, with another LLM technique called embedding language models, that converts textual data into numerical representation and stores it in a vector database. Please consider that this is also a huge transformation step. This is due to the fact that you need to have the data and also at best to store it in LLM-friendly format, e.g. format that the LLM understands. In this way, retrieving this data later and giving it back on the LLM will be a more smooth and time efficient approach.
- Retrieve the relevant context information - in this step, the original prompt that is in a text format is transformed into a vector representation and matched with the vector databases.
- Augment the prompt for the LLM - in this step RAG augments the original prompt by adding the retrieved specific information.
- In addition, you need to keep your extra knowledge source up to date as well.
Technology Decisions and Use Case
I am going to demonstrate how to build RAG using Spring AI with text input.
For this use case you have to make two important technology decisions. The first and major one is to choose the LLM. After knowing the LLM, you have explicitly defined the Chat Client (receiving prompts from the user) and the Embedding model. The second one is to choose the Vector datastore.
First Decision LLM Model - Azure Open AI Services
In general, using Open AI directly or via Azure uses the same LLM. What I found interesting in Azure, is that it can actually be more cost-effective in comparison to choosing directly the Open AI API. Thus, I have decided to use Azure. Another benefit is having the possibility to choose the region for the deployment of the models. In order to run the examples locally, in the proof of concept app, you need to have an Azure account. Afterwards, register subscription for Open AI Services (I have chosen pay as you go) and create the resource.
This however is not sufficient. You need to make a deployment of the Open AI model you would like to use. For the use case, I will be using the Embedding model text-embedding-3-small. A very important part to consider is the availability of models based on the region you are. I have chosen the westeurope region which comes with not full availability of the latest models. If you are developing a business application to run in production, this is a very important aspect to consider. For a basic use case, the older model should be sufficient. In the linked table, you can get a good overview of what is supported in which region: Azure-model-summary-table-and-region-availability. Please note that this information can change dynamically.
Second Decision Vector Store - PgVector
Since PostgreSQL is widely used and PgVector is its open source extension for a vector store, I have decided that this is a good match for the application. There are many other options out there, doing a detailed comparison of the vector store is out of scope for this blog post. Before delving deeper, I would like to make a brief introduction into Vector databases. Unlike traditional Relational databases, Vector databases function differently. They accept a vector as a query and search for similarities. The result given back has the higher similarities. Details on how this works can be found here: Spring AI Vector Database.
Demo Project RAG with Spring AI - Deep Dive
Github Repository
For the Demo Project please check out the following Github Project: RAG with Spring AI Demo and follow the instructions in the README on how to configure it.
Dependencies Overview
- To be able to integrate RAG with Azure and OpenAI, you will need
org.springframework.ai:spring-ai-starter-model-azure-openai. - To be able to use PgVector as a database, you will need
org.springframework.ai:spring-ai-starter-vector-store-pgvector. - Lastly, to be able to use the Advisors from Spring AI, you need an extra dependency
org.springframework.ai:spring-ai-advisors-vector-store
dependencies {
implementation("org.springframework.boot:spring-boot-starter-web")
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
implementation("org.jetbrains.kotlin:kotlin-reflect")
implementation("org.springframework.ai:spring-ai-starter-model-azure-openai")
implementation("org.springframework.ai:spring-ai-starter-vector-store-pgvector")
implementation("org.springframework.ai:spring-ai-advisors-vector-store")
testImplementation("org.springframework.boot:spring-boot-starter-test")
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
Configuration Overview
-
Getting the right configuration is essential for having a working example. My goal is to have the minimum needed that makes a good demo example. For getting the right configuration between Azure and Spring AI, the LLM models that are going to be used must be deployed. It is crucial that the Chat client and the Embeddings model come from the same provider and are both deployed. The Chat client is needed for sending a prompt to the LLM. The Embeddings are needed for getting a vector representation of the extra context that will be provided the LLM. For this please follow the well documented from Azure official source: Azure-how-to-deploy-model. The final result should look like this:
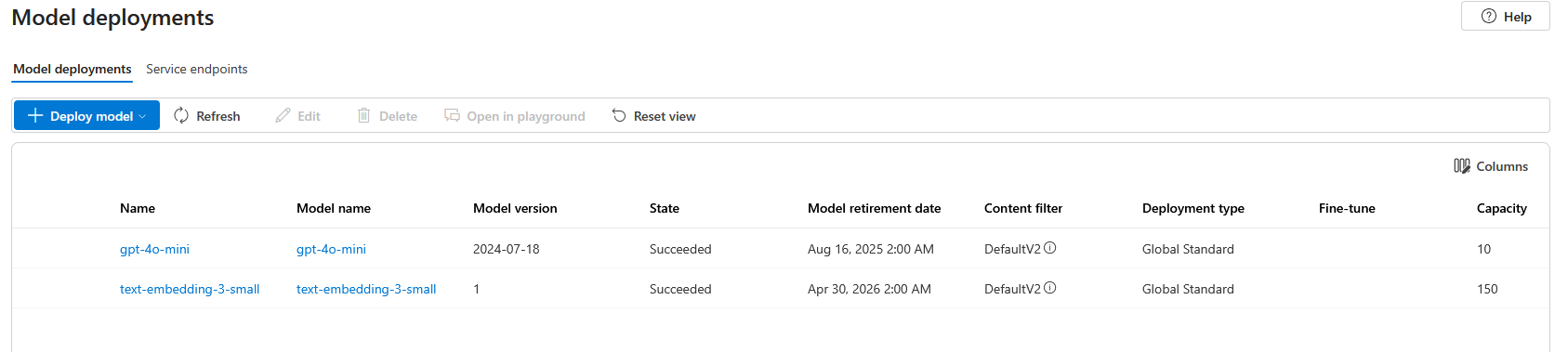
-
Afterwards, you need to add the correct endpoint, api-key and deployment-name of Chat client and Embeddings model.
spring: ai: azure: openai: # The Key from Azure AI OpenAI Keys and Endpoint section under Resource Management api-key: # The Key from Azure AI OpenAI Keys and Endpoint section under Resource Management endpoint: embedding: options: deployment-name: text-embedding-3-small # Azure deployment (not model) name chat: options: deployment-name: gpt-4o-mini # Azure deployment (not model) name -
Setting the schema initialisation to true is another important configuration.
spring: ai: vectorstore: pgvector: initialize-schema: true #schema-validation: trueYou can read more about it in the official Spring documentation: Spring Vector Databases. During testing with the latest Spring AI Version, schema validation must not be set to true explicitly, when using the defaults provided by Spring.
Implementation Overview
- In package
serviceis located theVectorStoreService. Its responsibility is to save the additional context into the Vector database. For the demo project I have used the Document object, which is very suitable for smaller amounts of data. A more advanced way would be to have the data in PDFs that are firstly loaded and then saved into the database. Before saving, theVectorStoreclass makes a call to the Azure Embeddings models for getting the vector representation.import org.springframework.ai.document.Document import org.springframework.ai.vectorstore.VectorStore import org.springframework.stereotype.Service @Service class VectorStoreService( private val vectorStore: VectorStore ) { /** * Creates embeddings and saves them into the vector store */ fun saveDocuments() = vectorStore.add(recipeDocuments) companion object { private val recipeDocuments = listOf( Document("Dessert option - vegan carrot cake with dark chocolate. This is the healthiest option."), Document("Dessert option - cardamom cinnamon rolls based on traditional recipe. This is middle healthy."), Document("Dessert option - low sugar vanilla ice cream with strawberries. This is also a healthy option due to its low sugar content.") ) } } - The starting point of the application is the
RecipeControllerlocated in packageapi. This is a Rest Controller that exposes the GET Endpoint/recipe-recommendationand receives the user prompt input as a query param. Firstly, theChatClientshould be configured to use theAzureOpenAiChatModeltogether with theQuestionAnswerAdvisorwhich makes sure the LLM searches into the Vector database.val chatClientCustom = ChatClient.builder(chatModel) .defaultAdvisors( QuestionAnswerAdvisor(vectorStore) ).build() } - Lastly, the user prompt is executed against the LLM and the response is retrieved.
val response = chatClientCustom.prompt() .user(promptInput) .call() .content() return PromptResponse( originalPrompt = promptInput, searchResult = response )
Final Test
To test the demo project please follow the instructions on how to configure, build and start the application - Demo Project Application Setup. I have prepared 3 tests - the first two show that response is taken from the context that is provided and not something else from the LLM. The last test demonstrates a user input that has no similarities with the provided context. Here, it can be observed that the LLM responds quite well and sends back that no information can be provided.
Test 1
-
Request
curl -G localhost:8091/recipe-recommendation --data-urlencode "prompt='I am looking for the healthies dessert.'" -
Response
{
"originalPrompt":"'I am looking for the healthies dessert.'",
"searchResult":"The healthiest dessert option from the context provided is the vegan carrot cake with dark chocolate."
}
Test 2
-
Request
curl -G localhost:8091/recipe-recommendation --data-urlencode "prompt='I am looking for a dessert based on traditional recipe.'" -
Response
{
"originalPrompt":"I am looking for a dessert based on traditional recipe.'",
"searchResult":"Based on the traditional recipes mentioned in the context, you might enjoy the cardamom cinnamon rolls. They are a delightful dessert option that incorporates traditional flavors. If you're looking for something healthier, the vegan carrot cake with dark chocolate is also a great choice. Let me know if you need more information!"
}
Test 3
-
Request
curl -G localhost:8091/recipe-recommendation --data-urlencode "prompt='I am looking for a cheesecake recommendation.'" -
Response
{
"originalPrompt":"'I am looking for a cheesecake recommendation.'",
"searchResult":"I'm sorry, but I can't provide a cheesecake recommendation based on the information provided."
}
Final Thoughts
In this blogpost I have covered the basic theory of the RAG pattern focused on Java developers who would like to try it out. What important decisions should be made when doing RAG were covered. Lastly, a concrete example of how this can be implemented using Spring AI API was presented.
Personally, I have enjoyed the learning experience. In my opinion the Spring AI API is developer friendly and I was happy to be able to test it locally together with the created Azure account for AI services. The LLM options that are supported are growing and I am looking forward to diving deeper into other providers. What I would also like to look at in a detail is processing PDFs on a large amount of data that has to be inserted into the vector store, which is crucial for business related applications. So, stay tuned!
Happy learning! 🙂